
プロセッサとメモリの関係
多くのプロセッサはデータを1Biteずつカットして、
メモリアドレスを割り振っていく(=バイトアドレッシング)。
メモリに割り当てたアドレスには4Biteずつデータを入れていく。
~なぜ4Biteか?~
多くのプロセッサは一度に処理できるデータ量が決まっており、
32bitプロセッサなら一度に32bit(=4Bite)までしか扱えない。
~なぜデータ量が決まっているか?~
多くのプロセッサは、プロセッサ内のレジスタを元に、数値演算を行っており、
一つのレジスタが一度に扱えるデータ量が32bitなら、32bitプロセッサになる。
~レジスタとは?~
データとかメモリアドレスを一時的に保存しておく場所で、CPUとかI/Oにある。
レジスタからメモリにデータが書き込まれる。
プロセッサの動作とは、レジスタとメモリとの間でデータを送受することだといえる。
以下イメージ図
8ビットプロセッサでの例。プロセッサからの命令でメモリアドレス00000011にデータ00011010を格納している。
I/Oからのデータは一旦プロセッサのレジスタに保存してから、メモリに書き込む感じ。
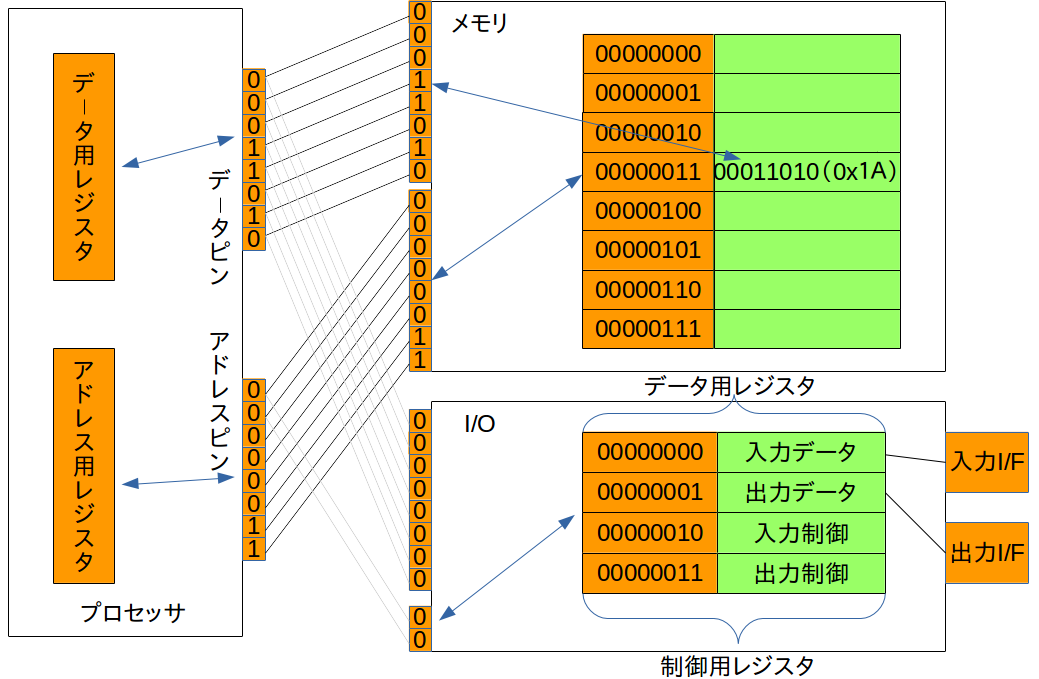
データをメモリにどう格納するか
Bite単位でメモリアドレスへ割り当てる方法をバイトオーダ(=エンディアン)という。
エンディアンには2種類ある。
・リトルエンディアン
(=最下位bitから、メモリの低位アドレスに入れていく。※下から入れる。)
ex) Intel x86プロセッサはこれらしい
・ビッグエンディアン
(=最上位bitから、メモリの低位アドレスに入れていく。※頭から入れる。)
ex) 一部Macはこれらしい
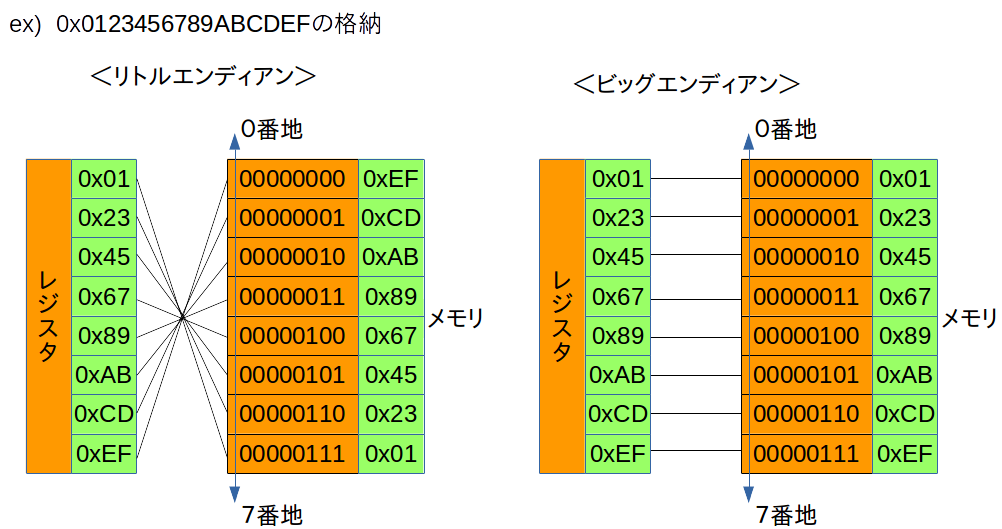
文字列をメモリアドレスへ格納する場合
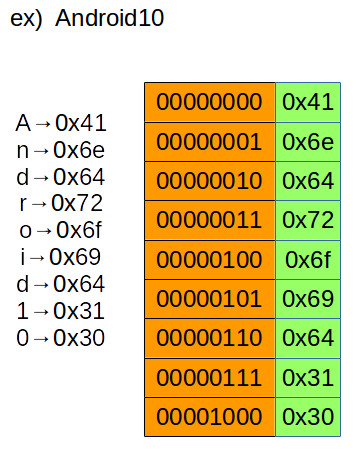
文字列は数値に変換されて格納される。
例としてASCIIコード表のAを変数に定義すると、
Aに紐付いた0x41が変数に代入されて、メモリアドレスに格納される。
Code = ‘A’
⇓
Code = 0x41
※1Biteで1文字を表すことができる
8bitで0〜255の数値が表現できるので、主要なアルファベットと数字と記号を、
数値と対応させて表現できる。
日本語(ひらがな、カタカナ、漢字)は文字に対応する数値がコード表にない場合、
既存の文字コードでとりあえず置き換えようとして、文字化けになることがある。
この場合Shift_JISとか別の文字コードが必要になる。
以下ASCIIコードでのイメージ
参考:矢沢久雄(2003)『コンピュータはなぜ動くのか』日経BP社



